ISUCON14に参加しました(チーム洋風海老名コミック、スコア21471、57位)
ISUCON14に、チーム洋風海老名コミックとして参加しました。最終スコアは21471。
今年は初挑戦の ![]() id:deflis55
id:deflis55 ![]() id:nakataki と一緒に、自分としては初挑戦の Node.js 実装で。インフラ担当だったんですが、途中でやることなくなったのでペアプロデバッグなどやってる時間の方が長かった気がします。
id:nakataki と一緒に、自分としては初挑戦の Node.js 実装で。インフラ担当だったんですが、途中でやることなくなったのでペアプロデバッグなどやってる時間の方が長かった気がします。
今回は遅いところを順に倒せばいいって問題じゃなくて、ユーザーの評判を気にしながら上げていくって感じでした。スコアを上げるために単純に遅いところを見ていくんじゃない感じがすごく面白かったです。問題作成大変そうですが、おつかれさまでした。
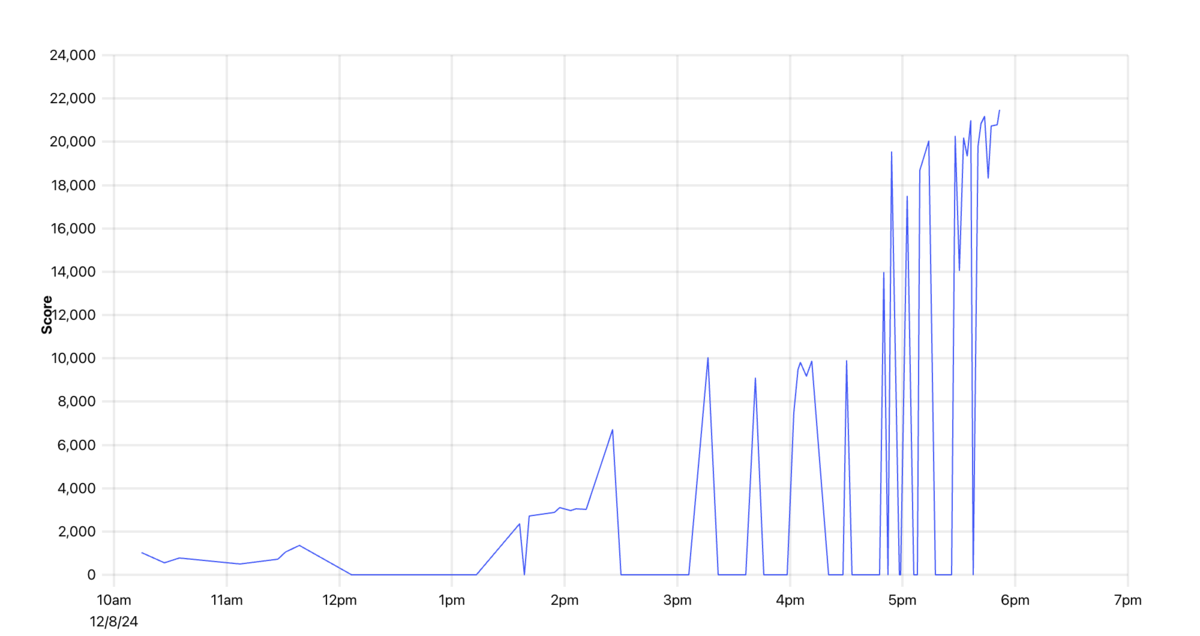
具体的なスコアはこんな感じ。綺麗にスコア履歴が3フェーズあって面白い。
- 初動はまず計測したりしつつ、椅子のマッチングを改善。
 id:nakataki が最初にデータを眺めて都市と椅子の位置を見てくれたのが本当によかった。苦戦しつつも昼休み明けに終わり、一気にスコアが上がる。
id:nakataki が最初にデータを眺めて都市と椅子の位置を見てくれたのが本当によかった。苦戦しつつも昼休み明けに終わり、一気にスコアが上がる。 - まだまだ時間に対する不満が高いので、DBボトルネックを解消するため重いクエリの原因になってる総走行距離情報を椅子に持たせつつDBサーバー分割したりなど。スコアが上がると決済リクエストのエラーが目立ったり、この辺は結構しんどかった。仕様読むの大事ね。
- そこまでやっても椅子が来るまでの時間の不満がまだまだ高いので、速度を考慮したアルゴリズムにしたり、
![]() id:deflis55 が実装をリードしてくれたし、
id:deflis55 が実装をリードしてくれたし、 ![]() id:nakataki がデータを見たりアルゴリズムを考えてくれたりと結構バランスいい動きがとれた気がします。
id:nakataki がデータを見たりアルゴリズムを考えてくれたりと結構バランスいい動きがとれた気がします。
おつかれさまでした。向き合って作業するの最近やらないけどいいですね。割とちゃんとスコアは出たけど、このメンバーならもうちょっと頑張れたなーと悔しいところ。来年また出直します。
リポジトリはこちらです。
github.com
問題面白かったし、ベンチマークも最後まで快適でよかったです。運営の皆様、大変だと思いますがありがとうございました。
SREは意思決定を助けてくれる
この記事は Mackerel Advent Calendar 2023 の10日目です。ちょっと出遅れてしまった、けど投稿日は無理やり調整しています。
今年のネタは今年のうちに供養するため、今年9月に開催された SRE NEXT 2023 というイベントで発表した内容の紹介です。発表資料はこちら。
speakerdeck.com
SREの考え方は最近だいぶ浸透してきたなと感じます。今年の SRE NEXT での発表も、大企業での導入事例や実際に運用・改善してきたふりかえりなど、実践的な内容が多くなってきてますね。いいことです。
一方で、世間を見渡すと、まだ導入の時に苦労していることも多いなと思います。普段 Mackerel を開発しているので、余計にそういう声が聞こえやすい立場でもあるかもしれません。SREの考え方っていうは組織に導入するものなのでトップが理解してると導入が楽ですが、そのためには何が嬉しいか、何が変わっていくのかもっと語られる必要があるかなと感じています。
信頼性は大事なので数字で語りたい
ユーザー視点での信頼性が大事、というのはプロダクトを作ってたら当然そう考えると思うんですよ。そのための判断も活動もチームは日々やっていると思います。
そんなプロダクト作りでは、日々いろいろなイベントが起きますし、いろんな判断による心の体力はガリガリ削られていきます。「こんどの新機能リリース、先日の障害の恒久対策、今ちょっとずつ遅くなってるAPIの調査、どれが大事か」などの状況はよくありますね。これを勘と経験と度胸で決めいってもいいんですが、大変だし他人に渡せない。何か判断軸が欲しくなります*1。
信頼性はどれくらい必要なのか、低下の時のアクションは。計測して数字で語ることで判断軸を共有できるし、改善も可能になります。数字で語るためのフレームワークが SLI/SLO になるわけですね。
SLO は意思決定すべきポイントを明確にする
SLO のプラクティスは、誰がどのタイミングで意思決定すべきかを明確にしてくれます。エラーや性能劣化についてチームで判断して対応すべきかどうか考えられる。ビジネスと接続するSLIの見極めと目標設定をうまくやることが次の仕事になる。大変な仕事であることはあまり変わりませんが、意思決定すべきポイントはここだ、と示してくれます。
信頼性や開発生産性を高められるって話はしてなくてうまくバランスを取るのが楽になる、と言ってます。これは普段判断することを仕事にしてる人はめちゃくちゃ嬉しいはず。少なくとも私はここが一番嬉しかったポイントです。
信頼性を高める活動はもちろん大事です。SREの別のプラクティスとして言われる、トイルの削減やソフトウェアによる運用の自動化は、プロダクトや開発・運用環境が良くしていくために取り入れるべきプラクティスですね。この辺は改めてSREって言われなくても取り組みやすいところかなと思います。
ちなみに発表中でも紹介していますが、 2023 State of DevOps Report | Google Cloud では信頼性が足りない組織はそんなに多くないという結果になっています。なんとなく感覚に合うと思いませんか。
詳しくは動画で
動画もあるようなので、資料と合わせて当日の様子はこちらをどうぞ。*2
www.youtube.com
以上、Mackerel Advent Calendar の10日目でした。
11日目は
宣伝コーナー
来週の Mackerel Meetup #15 Tokyo でも SRE のセッションやります。自分とは違う切り口で語ってもらえると思うので興味ある方はぜひ来てください、懇親会で語りましょう。
mackerelio.connpass.com
ISUCON13に参加した(マルチタスクマスタリーサーバーズ) #isucon
ISUCON13 に ![]() id:polamjag
id:polamjag ![]() id:Gurrium と「マルチタスクマスタリーサーバーズ」というチームで参加しました。
id:Gurrium と「マルチタスクマスタリーサーバーズ」というチームで参加しました。
isucon.net
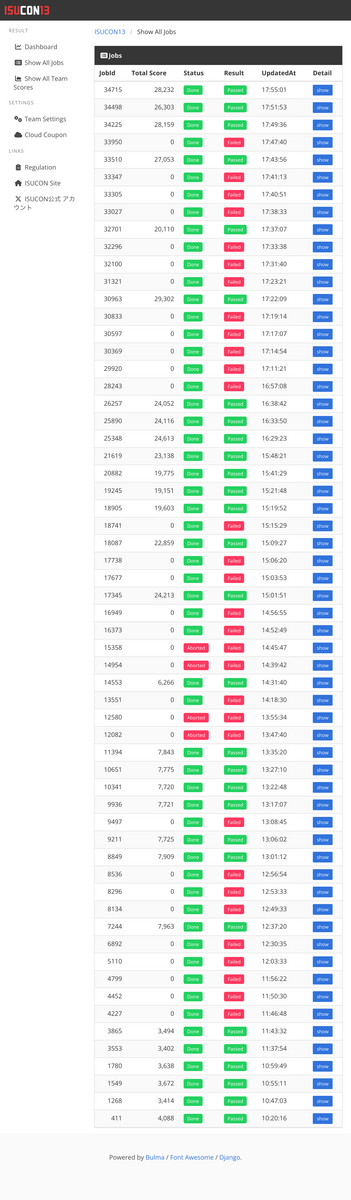
スコアは28,232点で全体70位です。もうちょっと伸ばしたかったなー、結構悔しさは残りました。リポジトリはGitHubに公開しています。
github.com
![]() id:polamjag とは前に何度か出たことがありますが、
id:polamjag とは前に何度か出たことがありますが、![]() id:Gurrium とは初めてかつ仕事上の絡みも少ないのもあり、例年に比べてしっかり(集まって1.5日くらいは+個人手ではもう少し)練習して臨んだのでした。それだけにもうちょっと上位に手をかけられるくらいに頑張りたかったなーというところですが、ここが今の実力なんだろう、また1年精進します。
id:Gurrium とは初めてかつ仕事上の絡みも少ないのもあり、例年に比べてしっかり(集まって1.5日くらいは+個人手ではもう少し)練習して臨んだのでした。それだけにもうちょっと上位に手をかけられるくらいに頑張りたかったなーというところですが、ここが今の実力なんだろう、また1年精進します。
やったこと
いつもの15分スプリントで スプリント会 会場 · Issue #4 · tatsuru/isucon13 · GitHub
- 最初の1時間は計測、デプロイ、問題観察など
- 12:37 index貼る + アイコン304 で 7244点
- 15:01 userstream, livestream の N+1 剥がす、DB分離で 24213点
- 17:43 PowerDNS をファイル配信にして 27053点
- 17:55 再起動試験して28232点
自分で手を動かしたのは最初のデプロイ・計測系とproxy、DB、DNS周り。アイコン配信考えるところ(実装は違う)、あとは他の2人の作業をペアで見るなど。
15時にスコアが跳ねたタイミングはたしか11位くらいで結構いい感じだったし、ここまでは作戦と動きも悪くなかった。自分の作業には余裕があったから他の2人の作業とコードもちょいちょい見に行ってたのが良かったかもしれない。
午後はあまりスコアが伸ばせてない。DNS水責め攻撃をちゃんと対策しようと思ってPowerDNSの設定をファイル配信に変更したんだけど、できたのが17:30過ぎでギリギリだし、サーバーも2台しか使えずに終わってしまったのがくやしい。チームとしても stats 関連や reaction の N+1 などは最後まで不具合が残ってしまって一通り revert することになったのが一番もったいなかった。自分もハマってたのであんまりフォローしに行ったり、ちょっと落ち着いてペアでみよう、みたいな話を持っていく気持ちの余裕も少なかった。
ちなみにpowerdnsをbindファイルに移行した ことで最後の名前解決数は178412と、DNS捌いたで賞に近いところには行けたのがちょっと満足です。launch=bindにして、zoneファイルは初期化とユーザー追加タイミングで更新とリロード。捌くほど負荷が上がるのは知ってたけど、結局最後まで負荷が上がり続けてCPUは食ってしまうし、攻撃を捌いても当然スコアは伸びないわけなのですが。
あとはただの感想
問題設定自体は、オープニング動画の演出含めて面白かったしフロントエンドも最初チラッと見てよくできてるなとも思ったけど、開いてるとポーリングだけでめちゃくちゃCPU食うので結局ほとんど見ずに終わってしまったけど。
kazeburoさんだからDNS水責めってのは絶対予想できたなー。いやそんなわけないだろうとも思ってたんですが。おかげで攻撃の厄介さは知ってたし、対策もなんとなく思い浮かびはしたので、あとは実装しきる力<<パワー>>だけですね。攻撃相手にレスポンス遅延させる、みたいなこと思いつきはするけどシュッとやれないもんな。
ベンチマーカーは順調な時は快適だったけど、止まってた時はちょっと困ってたかも。デバッグや仕様チェックはベンチマーカーで回してるからね。運営は(やったことあるので想像つくんですが)めちゃくちゃ大変だと思うのですが、いいイベントだと思うので継続は応援したいです。
さくらのクラウドシェルで mackerel-agent を動かす
さくらのクラウドシェルというのが出ていたので遊んでみます。ログインしなくても使えますが外向きの通信ができないので、会員ID持ってる人はログインして遊んだ方が楽しめます。
www.sakura.ad.jp
起動するといい感じのシェルが立ち上がります *1 。sudo もできる
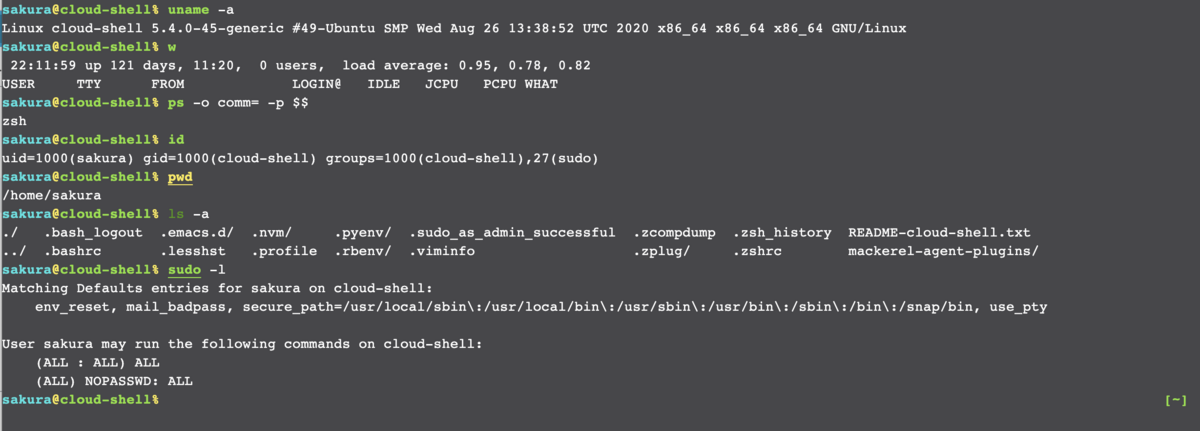
シェル周りちょっと手が加わってる感があり快適です。Ubuntu で普通に apt が動くので色々入れられます。
さくらのクラウドシェルは、ブラウザから無料で利用できるオンラインのシェル環境です。開発者向けの環境がプリインストールされているため、使い慣れたツールをすぐに利用できます。
さくらのクラウドシェル | さくらインターネット
mackerel-agent を入れてみる
というわけで入れてみましょう。Mackerel のスタートガイドのここにあるコマンドコピペして入れてみます
(API Keyうつってますが削除済みです)
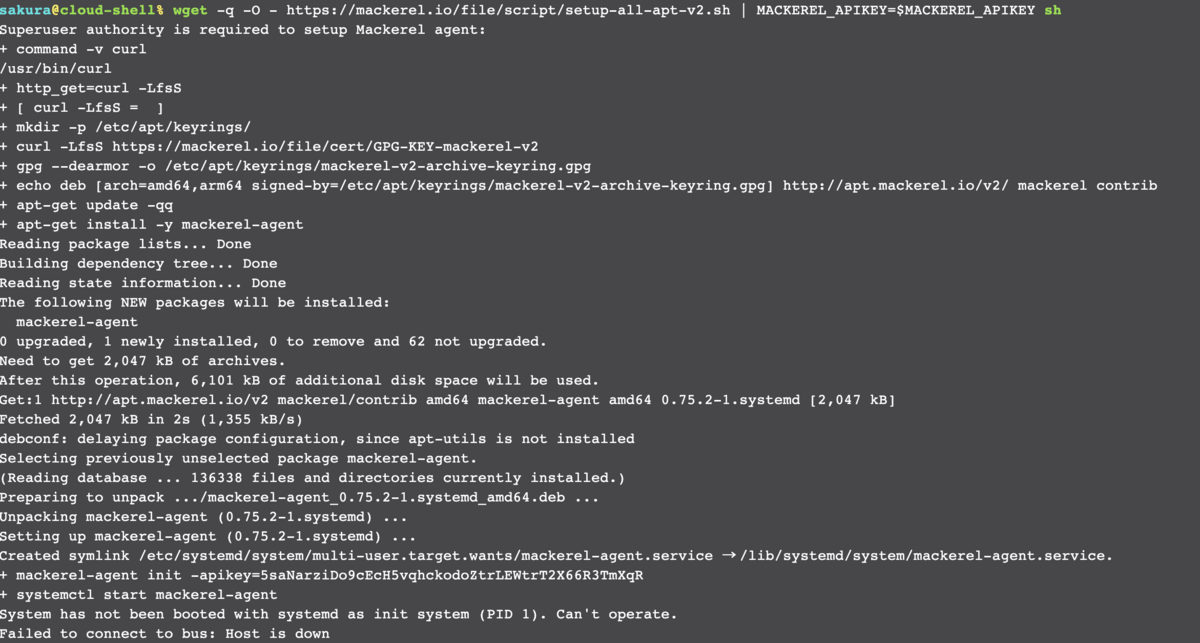
systemd がなかったので今回はとりあえず手で起動

無事にホストが登録されました
他の使い方
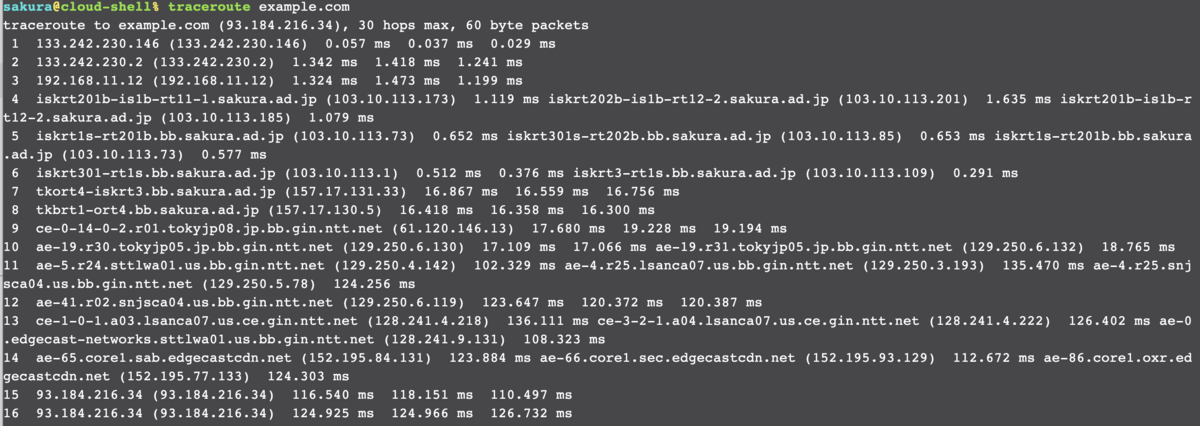
外向きの通信が通るということでネットワーク経路見るのは便利ですね。さくらクラウドにインスタンス上げなくてもいいので調査などちょっと捗りそう。
go や terraform など入ってるので、チュートリアルレベルのやつをサクッと動かすのはすぐにできます。ただし、重ためなリポジトリを持ってきてビルドとテストを回したりするとすぐ20分経過してコンテナ落とされるので、あんまりしっかりした作業は向かない感という感触でした。
ちなみに
ログイン画面へのリダイレクトがめっちゃよかったです。誰でもここを通るはずの場所に配置しとくのがうまいな。
さくらのクラウドシェルのAAっぽいログイン誘導画面めっちゃいいな pic.twitter.com/n5rIdUc9hB
— tatsuru (@tatsuru) 2023年5月26日
AWS Solution Architect Professional を取得した(3.5年ぶり2回目)
AWS Solution Architect Professional 試験に合格しました。前回が 2019/11 だったので3年半弱ぶり。3年で失効なので実はちょっと切れてたんだけど、ちょうど試験が更新されるタイミングだったのもあって待ってから受けてみた。無事に合格してほっとしている。
前に受けた時の記録はこれ。
wtatsuru.hatenadiary.com
前回の記憶はだいぶ曖昧なんだけど、前にも増してガバナンスやセキュリティ、組織でAWSを使うための基盤作りを行うための問題に寄ってたなという印象は持った。
勉強
いつも通り会社で有志を集めて勉強会を企画してやっている。毎週多少意識が向くようにしつつ、日程を決めるためのきっかけにした。結局直前に詰め込みはすることになる。
試験が更新されたばかりということもあって教材は揃ってないので、準備はほぼ全て公式の AWS Skill Builder と関連する Blackbelt Seminar でやった。
aws.amazon.com
Skill Builder すごくいいんだけど、一つだけ不満が。有料サブスクの支払いがAWS連携しかない?かつ、連携しようとすると root アカウントでのログインを求められてしまうところ。rootアカウント非推奨じゃないのと思うし、会社の経費で出そうとすると大変。以前のようにカードで払いたいな。
ISUCON12予選に参加しました
ISUCON12に、![]() id:tkzwtks
id:tkzwtks ![]() id:yashigani_w と「デジタルトランスフォーメーションズ」というチームで出場してきました。最終スコアは4159で本選進出ならずという結果でした。
id:yashigani_w と「デジタルトランスフォーメーションズ」というチームで出場してきました。最終スコアは4159で本選進出ならずという結果でした。
isucon.net
![]() id:tkzwtks
id:tkzwtks ![]() id:yashigani_w の2人は同じ会社で一緒に働いて長いんですが、同じチームで仕事したことはほぼなかったので、なかなか楽しい体験だったなと思います。問題も運営もすごく良かったので感謝です。
id:yashigani_w の2人は同じ会社で一緒に働いて長いんですが、同じチームで仕事したことはほぼなかったので、なかなか楽しい体験だったなと思います。問題も運営もすごく良かったので感謝です。
それはそれとして、本戦いけなかったのはだいぶ悔しい。なかなか向き合えなくて、この記事を1週間書けなかったのでした。なんとか7月中には書いたよ。
ふりかえり
正しさの追求の気持ちが足りないかも、というのを終わった後に会社の他のメンバーと話してて感じた。
プロダクションコードならこんなの絶対やらないでしょ、というところも意図があると考えて後回しにしがち。謎の採番を見ても放置したり、flock を温かい目で眺めたり。性能は悪くないかもしれないが、SQLite のままじゃ自分の土俵で戦えない。もっと理想に近づけていく、最強になる気持ちを取り戻したい。
- 作戦はそこまで間違ってなかった、と思う。状況は見えてたし、やってたところは外してない。
- 手の速さと正確さは課題
- インフラ領域だと、デプロイまでは「いつもの」のはずなのに2時間かけてる。メモリリークの原因切り分けられなかったのは敗北感が強い...。
- スコアキャッシュのとこの実装も遅かったし、もっとシャッと書けると手数増やせたなと。正しいことを素早くやろう。
- チームとしての雰囲気がよかった
- 15分スプリントで頻繁に見直し、毎回掛け声を上げる。うおお。
- 対面なら雰囲気は見えるので、中盤など多少インターバル長くても行ける気はする。
- 対面作業の強さを思い出した
- 任意のペア作業可能が瞬時にできるようなディスプレイ配置、顔が見えるので詰まってることもわかる。ホワイトボードで状況共有。
- チーム作業はリモートに比べて圧倒的に有利だなと改めて実感した。
自分の流れの振り返り
リポジトリはこちら。
github.com
- 15分スプリントを持ち込んだ。ふりかえりにも便利ですね スプリント会 · Issue #3 · tatsuru/isucon12-yosen · GitHub
- まずはインフラ担当として序盤の整備 インフラ作業スレ · Issue #7 · tatsuru/isucon12-yosen · GitHub
- 起動、計測、デプロイあたりの環境を整える。docker-compose だけどアプリしか使ってないのでそのまま放置。
- 昼の作戦会議
- ランキング改善のための余計なデータ削減。SQLite はそのまま使う。
- サーバー分散やら全体の作戦整理、時々ペアでバッグ
- 最終スコアをキャッシュして速くするってやつをやりかける
- 他が詰まってたので別ラインでキャッシュするコードを書いてた。最終的には出さなかった。
- 最後はメモリ詰まって落ちるやつを見てた
チームメンバーとの相互リンク
Mackerel の2021年
Mackerel のプロダクトマネージャーをしている ![]() id:wtatsuru です。
id:wtatsuru です。
Mackerel この記事は Mackerel Advent Calendar 2021 25日目の記事となります。昨日は ![]() id:ryuichi1208 さんによる Mackerelに入門して半年経ったので感想ややったことなど - 地方エンジニアの学習日記 でした。今年から始めてプラグインまで作っていただいててすごい。
id:ryuichi1208 さんによる Mackerelに入門して半年経ったので感想ややったことなど - 地方エンジニアの学習日記 でした。今年から始めてプラグインまで作っていただいててすごい。
今年も Advent Calendar に色々な記事が集まりました。中の人の話から、長年使っていただいてる方、また今年から使い始めたという話まで。Advent Celendar 最後の記事として、いくつかトピックを取り上げつつ今年のMackerelを振り返っていこうと思います。
まず今年 Mackerel で反響が大きかったものとして、 Terraform Provider のリリースが挙げられます。Advent Calendar でも、利用例 やデバッグ方法 などが紹介されていました。Mackerel は元々 mkr monitors コマンドなどでコード管理のサポートはしていたのですが、現代の IaC ツールとしては少し物足りないものでした。元々有志の方が一部作っていただいていた実装があったため、作者の方にお声がけして公式実装としてリリースしたものです。監視ルールの管理などで特に便利なものとなっていますので、ぜひご利用ください。
mackerel.io
SLI/SLOへの取り組みもいくつか紹介いただきました。世間的にも実践例が増えてきた分野ですね。SLO の運用をやろうとすると最初に考えることが多いのですが、shimesaba はそういったスタートを助けてくれるすごく良いツールです。
techblog.kayac.com
はてな、Mackerel本体の運用でもSLI/SLO運用は実践しており、足りないパーツを補いつつ、ある種の型を提供していきたいと考えています。17日目の以下の記事では、社内での運用事例を紹介しています。社内での運用事例は、今年夏のデブサミでも発表していますのでぜひご覧ください。 はてな「Mackerel」のSREに学ぶ、開発パフォーマンスと信頼性のベストバランスとは?【デブサミ2021夏】 (1/2):CodeZine(コードジン)
mackerel.io
このパーツの一つとして、ログをメトリック化して扱うツールも実験的に公開しています。過去にはOS上で動くプラグインという形式での提供が多かったのですが、今回は AWS上で動く Terraform module という形式で公開しています。
susisu.hatenablog.com

メトリックといえば、以前はホストの退役後もそのロールでカスタムメトリックのデータが利用できるようになりました。地味な部分ですが、コンテナ環境などホストが頻繁に入れ替わり前後で変わらずロール全体での傾向を見ておきたい、長期的な傾向が知りたい、というケースでもお使いいただけます。
mackerel.io
そのほか内部の話としては、フロントエンドフレームワークのReactへの置き換えも徐々に進んでいます。見た目にはほぼ影響がないのですが、一部表示が速くなるなどの改善も出ています。普段使いするサービスとして快適に使ってもらえるように取り組んでいきます。
developer.hatenastaff.com
クラウドを前提とした運用環境が定着してきて、SREの実践についても徐々に事例が増えつつあります。Mackerel としても、徐々にそういった環境へのサポートを強化し、道筋を提供していきたいと考えています。引き続きMackerelをよろしくお願いします。
